 Executing the door opening skill in the kitchen environment
Executing the door opening skill in the kitchen environment
Abstract
Agents building temporally abstract representations of their environment can better understand their world and make plans on extended time scales with limited computational power and modeling capacity. Existing methods for learning world models either operate per timestep or assume a fixed number of timesteps for abstraction. Our approach simultaneously learns variable-length skills and temporally abstract, skill-conditioned world models from offline data. This leads to much higher confidence in dynamics predictions allowing zero-shot online planning by composing skills for new tasks. Furthermore, compared to policy-based methods, this approach offers a much higher degree of robustness to perturbations in environmental dynamics.
Overview of offline skill learning
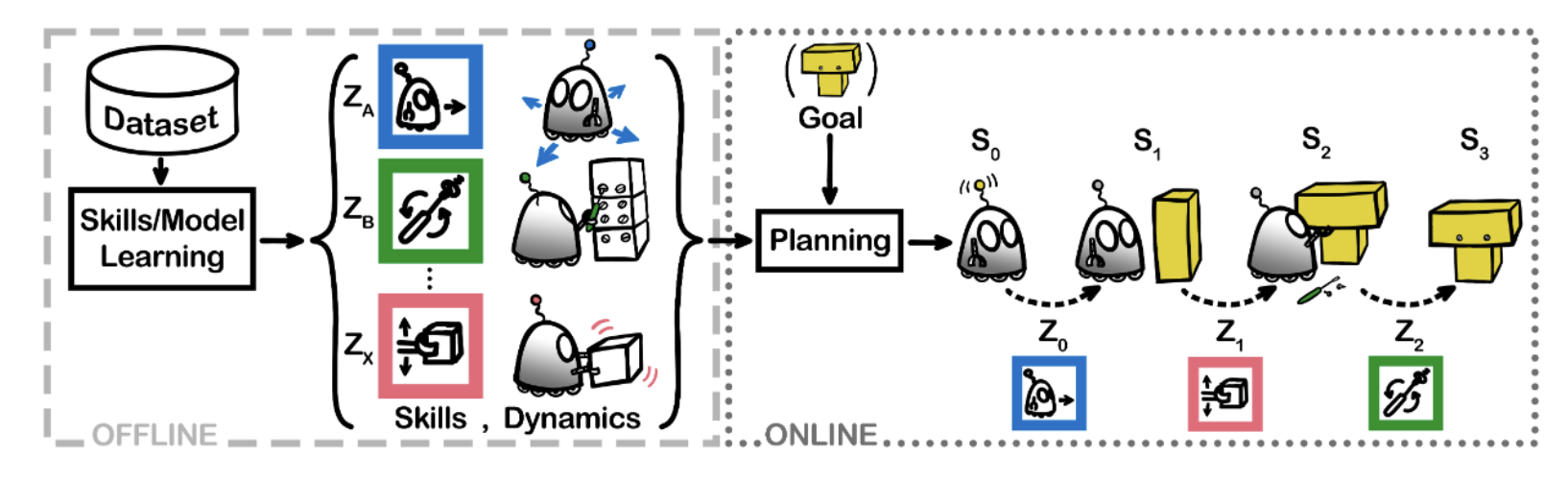 During the offline training phase, our algorithm automatically extracts semantically meaningful skills and skill conditioned dynamics model from the offline data. During the online planning phase, the planner uses the learned skill conditioned dynamics model to plan a sequence of skills to achieve the goal.
During the offline training phase, our algorithm automatically extracts semantically meaningful skills and skill conditioned dynamics model from the offline data. During the online planning phase, the planner uses the learned skill conditioned dynamics model to plan a sequence of skills to achieve the goal.
Legend
Notation
- Environment state: $s$
- Action: $a$
- trajectory: $\tau$
- skill: $z$
Components
- Skill prior: $z \sim p_{\omega}(z | s_0)$
- Abstract dynamics model: $s_T \sim p_{\psi}(s_T | s_0, z)$
- Lower level policy: $a_t \sim \pi_{\theta}(a_t | s_t, z)$
- Termination predictor: $b_t = p_{\phi}(s_t, z, s_T) > 0.5$